Text 2 Image Generation - Stability AI
This blog post provides an overview about the process of producing image using a provided text and describes how stability AI deploys their top model SDXL turbo in the Text 2 Image Generaiton process.
AI IN THE CONSTRUCTION INDUSTRY
Mohamed Ashour
1/1/20249 min read


Introduction
Text-to-image generation is a fascinating field of artificial intelligence that allows computers to convert textual descriptions into visual representations. In this blog post, we will explore this innovative technology, its applications, and the latest developments in the field, including Stability AI's groundbreaking open-source model, SDXL Turbo.
This artcile tackles the following ideas:
Understanding the Text-To-Image concept
Text-To-Image Generation in the construction industry
Models used in Text-To-Image Generation
Alternatives for Text-to-Image Generation
Stability AI's Latest Initiative: SDXL Turbo
Code for Text-To-Image Generation
SDXL Turbo Limitations
Useful Links
Understanding the Text-To-Image concept
Image generation from text is a process that involves converting natural language descriptions into visual representations using artificial intelligence techniques, specifically deep learning models like GANs (Generative Adversarial Networks). Here's an overview of the process:
1. Data Collection and Preprocessing: First, you need to collect a large dataset of images along with their corresponding text descriptions. This can be done by scraping websites or using existing datasets such as Flickr8k (8000 images) and Flickr30k (30000 images). The data is then preprocessed, usually by converting the text into a vector representation like word embeddings.[3]
2. Training Data Generation: To train an image generation model, you need to create pairs of text descriptions and their corresponding images. This can be done using techniques such as text-to-image synthesis or by employing human labelers who manually generate images based on the given texts.[2]
3. Model Architecture: Next, you choose a suitable deep learning architecture for your model. In this case, GANs are widely used due to their ability to produce high-quality and diverse outputs. The two main components of a GAN are the generator (G) that creates new images from random noise, and the discriminator (D) that determines whether an image is real or fake.[1]
4. Training: During training, the model learns by iteratively refining its ability to generate realistic images based on text descriptions. The process involves updating both G and D models in an alternating manner using gradient descent optimization techniques like Adam or RMSprop.[1]
5. Inference: Once the model is trained, you can use it for generating new images from a given text description by providing the input to the generator (G) component of your model. The output will be a visual representation that closely resembles the original text description.[2]
6. Post-processing and Evaluation: After obtaining the generated image, you may need to apply post-processing techniques such as denoising or color adjustments for better quality. Additionally, it's essential to evaluate your model's performance using metrics like Frechet Inception Distance (FID) or Inception Score to ensure that the images produced are of high quality and diverse in appearance.[2]
Text-To-Image Generation in the construction industry
Text-to-image generation can be a valuable tool for quantity surveyors in several ways:
1. Visual Documentation: It can help in creating visual documentation of construction sites or project components from textual descriptions. This visual aid can be crucial for accurate surveying and estimation [20].
2. Enhanced Communication: Text-to-image AI can facilitate better communication between quantity surveyors and other stakeholders. By converting complex textual data into images, it can make it easier to convey and understand specific details of a project [21].
3. Automated Document Generation: As per the capabilities of AI in automating tasks, text-to-image generation can assist in automatically generating visual elements for reports and documents related to quantity surveying and estimating [22].
4. Concept Visualization: For early-stage project planning, text-to-image AI can help quantity surveyors visualize concepts or proposed designs, aiding in more accurate forecasting and planning [23].
5. Error Reduction: By providing a visual representation of textual data, this technology can help in reducing errors that might arise from misinterpretation of text-only descriptions [24].
Models used in Text-To-Image Generation
There are several alternative models for text-to-image generation, each with its own advantages and limitations. Here is a brief overview of some popular approaches along with their sources:
1. Generative Adversarial Networks (GANs): GANs have been widely used in the field due to their ability to produce high-quality images that closely resemble the original text description. They consist of two main components, a generator and a discriminator, which are trained simultaneously in an adversarial manner.[4]
2. Variational Autoencoders (VAEs): VAEs are another popular approach for text-to-image generation, which use a latent space to encode and decode images into their corresponding text descriptions. They can produce diverse outputs but may struggle with high-quality image synthesis compared to GANs.[5]
3. Diffusion Models: Recently, diffusion models have gained popularity for text-to-image generation due to their ability to produce high-quality images with diverse content and styles. They use a Markov chain process that gradually adds noise to an image while maintaining its structure, allowing the model to learn from noisy data effectively.[2]
4. Transformers: Transformer-based models have also been applied to text-to-image generation, leveraging the attention mechanism's ability to capture long-range dependencies in both text and image domains. These models can produce diverse outputs but may struggle with high-quality image synthesis compared to GANs or diffusion models. [6]
5. StyleGAN Models: StyleGAN is a popular family of GANs that use an adaptive instance normalization layer to control the style and structure of generated images, allowing for high-quality image synthesis with diverse content and styles.[7]
These models have different strengths and weaknesses, so it's essential to choose the appropriate model based on your specific use case and desired output quality.
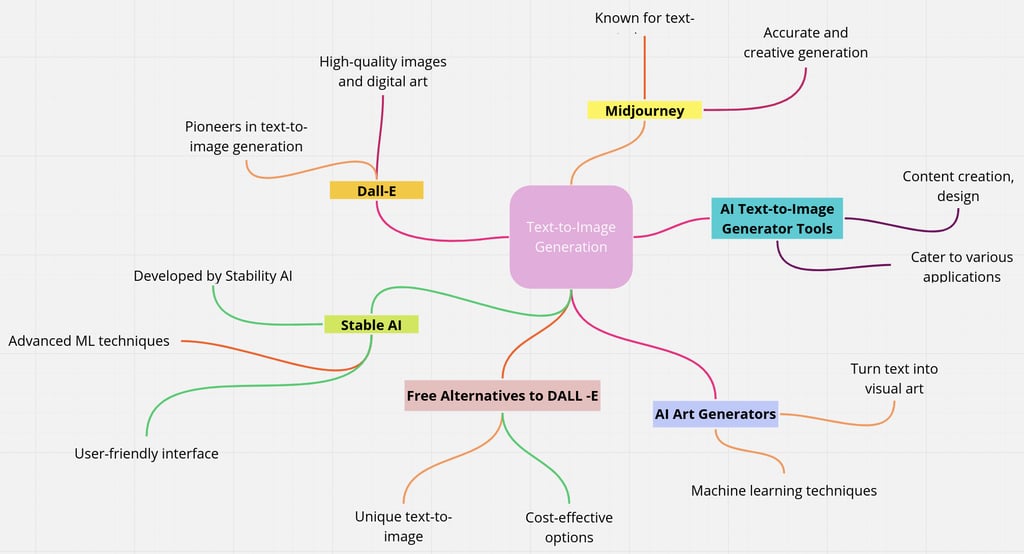
Alternatives for Text-to-Image Generation
Text-to-image generation has seen significant advancements in recent years, and there are several alternatives available for those seeking to generate images from text prompts. These alternatives cater to different needs and preferences, and here, we'll delve deeper into them:
1. Stable AI Diffusion - Developed by Stability AI, Stable Diffusion is a powerful AI art generator. It uses advanced machine learning techniques to create images based on textual descriptions. This alternative offers a user-friendly interface and impressive image generation capabilities.[8]
2. Dall-E Alternatives - DALL-E was one of the pioneers in text-to-image generation, and while it remains popular, there are alternatives worth exploring. These alternatives offer unique features and capabilities, allowing users to create high-quality images and digital art.[9]
3. AI Text-to-Image Generator Tools - There are various AI text-to-image generator tools available, each with its strengths. These tools cater to a wide range of applications, including content creation, design, and more. Users can choose tools that best suit their specific needs.[10]
4. AI Art Generators - AI art generators, in general, have gained popularity for their ability to turn text into stunning visual art. They employ machine learning algorithms to generate images that match the given text prompts, making them valuable for creative endeavors.[11]
5. Midjourney Alternatives - Midjourney is known for its text-to-image feature, but there are alternatives that offer accurate and creative image generation capabilities. These alternatives are worth exploring for those seeking powerful text-to-image solutions. [12]
6. Free Alternatives to Dalle-3 - For those looking for cost-effective options, free alternatives to Dalle-3 provide unique and robust text-to-image features. These alternatives cater to various user needs and offer alternatives to expensive paid solutions.[13]
In summary, the world of text-to-image generation is filled with diverse alternatives, each with its own set of features and capabilities. Whether you're a creative artist, a content creator, or someone with a specific application in mind, exploring these alternatives can help you find the best fit for your text-to-image generation needs.
SDXL Turbo Limitations
The generated images are of a fixed resolution (512x512 pix), and the model does not achieve perfect photorealism.
The model cannot render legible text.
Faces and people in general may not be generated properly.
The autoencoding part of the model is lossy.
Useful Links
For more information about SDXL Turbo model you can checking the following links:
Information about Stability AI from the Huggingface website https://huggingface.co/stabilityai/sdxl-turbo
Main Stability AI website contining the full explanation of the SDXL model - https://stability.ai/news/stability-ai-sdxl-turbo
Webapp for SDXL image generation - https://clipdrop.co/stable-diffusion-turbo
Stability AI have a paid online tool for image generation as well as editing existing tools. More information about the tool and the relevant pricing could be found in the following link: https://clipdrop.co/pricing
Sources
[Image Generation from Text with GANs](https://arxiv.org/abs/1710.10438) - A seminal paper on text-to-image synthesis using GANs.
[Text-to-Image Synthesis with Diffusion Models: Generative Foundation Models for Multimodal AI](https://arxiv.org/abs/2105.06387) - A more recent approach to text-to-image synthesis using diffusion models, which have shown promising results in the field.
[Flickr30k Dataset: Text and Image Data for Evaluating Visual Grounding](https://www.robots.ox.ac.uk/~vgg/data/flickr/) - A popular dataset used for training text-to-image models.
[Image Generation from Text with GANs](https://arxiv.org/abs/1710.10438)
[Text-to-Image Synthesis via Latent Variable Models](https://arxiv.org/abs/1609.05348)
[Text2Image: Transformer-Based Text-to-Image Generation](https://arxiv.org/abs/2104.08976)
[StyleGAN: Towards Adaptive Representation Learning of Human Face Identi](https://arxiv.org/abs/1802.07048)
(https://www.bitrix24.com/articles/11-best-midjourney-alternatives-for-ai-image-generation-2024.php)]
https://www.perfectcorp.com/consumer/blog/generative-AI/midjourney-alternative-app
https://medium.com/@thebasedai/exploring-the-top-6-free-alternatives-to-dalle-3-in-2024-2d7309146f33
[Stability AI - Introducing SDXL Turbo](https://stability.ai/news/stability-ai-sdxl-turbo)
[Hyscaler - SDXL Turbo: The Real-Time AI Image-Synthesis Model](https://hyscaler.com/insights/sdxl-turbo-real-time-ai-image-synthesis/)
[LinkedIn - Stability AI's Post - Introducing SDXL Turbo](https://www.linkedin.com/posts/stability-ai_introducing-sdxl-turbo-a-real-time-text-to-image-activity-7135355792337096704-uwc4?trk=public_profile_like_view)
[Ars Technica - Stable Diffusion XL Turbo can generate AI images as fast](https://arstechnica.com/information-technology/2023/11/stable-diffusion-turbo-xl-accelerates-image-synthesis-with-one-step-generation/)
[LinkedIn - Johari Abdullah's Post - Introducing SDXL Turbo](https://www.linkedin.com/posts/johariabdullah_introducing-sdxl-turbo-a-real-time-text-to-image-activity-7135635032517332993-lD3M)
- [linkedin.com - How to Evaluate Text-to-Image Generation with Neural](https://www.linkedin.com/advice/3/how-can-you-evaluate-neural-network-performance-txv4e
[arxiv.org - Using Text-to-Image Generation for Architectural Design](https://arxiv.org/pdf/2304.10182)
[texta.ai - AI writing assistant for Quantity Surveyor](https://texta.ai/ai-writing-assistant/building-and-construction/quantity-surveyor)
[addepto.com - Text-to-image AI - Benefits for Business](https://addepto.com/blog/how-businesses-can-take-advantage-of-text-to-image-ai/)
[springer.com - Text-to-picture tools, systems, and approaches: a survey](https://link.springer.com/article/10.1007/s11042-019-7541-4)
[researchgate.net - exploring the role of text-to-image ai in concept generation](https://www.researchgate.net/publication/371694765_EXPLORING_THE_ROLE_OF_TEXT-TO-IMAGE_AI_IN_CONCEPT_GENERATION)




Stability AI's Latest Initiative: SDXL Turbo
Stability AI's latest initiative, SDXL Turbo, represents a significant advancement in the field of text-to-image generation. Here, we delve deeper into this groundbreaking model, its features, and its impact on the world of AI image synthesis.
SDXL Turbo, introduced by Stability AI, is a real-time text-to-image generation model that was unveiled in November 2023. It is built upon a novel distillation technique known as Adversarial Diffusion Distillation (ADD) [14]. This approach enables the model to generate realistic images in a single step, making the image synthesis process incredibly efficient and fast.
Key features and highlights of SDXL Turbo include:
1. Real-Time Image Generation: SDXL Turbo's ability to create images in real-time sets it apart. It can generate detailed and high-quality images as quickly as you can input text prompts [17].
2. State-of-the-Art Performance: This model achieves state-of-the-art performance in text-to-image generation, ensuring that the generated visuals are both accurate and visually pleasing [16].
3. Open-Source: Stability AI's commitment to openness and accessibility is evident through SDXL Turbo's open-source nature. This allows developers and researchers to utilize and contribute to the model, fostering innovation in the field [14].
4. Wide Range of Applications: SDXL Turbo has diverse applications, including content creation, design, art generation, and more. Its versatility makes it a valuable tool for various industries and creative endeavors [15].
5. User-Friendly Interface: Stability AI has designed SDXL Turbo with a user-friendly interface, ensuring that users can easily input text prompts and obtain visually stunning results [18].
In conclusion, Stability AI's SDXL Turbo is a game-changer in the world of text-to-image generation. Its real-time capabilities, state-of-the-art performance, and open-source nature make it a valuable asset for anyone seeking to generate high-quality images from textual descriptions. This innovative model has the potential to revolutionize various industries and creative fields.
Code for Text-To-Image Generation
SDXL code could be deployed locally on your machine in your preferred IDE. For the purpose of this article, I have used Visual Studio Code. The code for using SDXL model is quite easy and straightforward. You have to make sure that you have the following packages installed:
Transformers
Torch - with CUDA enabled (https://pytorch.org/get-started/locally/)
Diffusers
The code starts by importing torch and difffusers package as per the code below.
import torch
from diffusers import AutoPipelineForText2Image
The second step is downloading the stability diffusion model and deploying it for our use case. The floating point 16 variant was used in order to provide more accuracy than 8-bit or 4 bit quantized models. The variant will directly affect the usage of GPU memory. The recommended is 16GB of Video memory
pipe=AutoPipelineForText2Image.from_pretrained("stabilityai/sdxlturbo",torch_dtype=torch.float16,variant="fp16")
pipe.to("cuda")
The third step is Creating a prompt variable which will contain the required prompt by the end user. After creating the image, the image is presented.
prompt = input("Enter the desired prompt or type exit to break the loop")
image = pipe(prompt=prompt,num_inference_steps=1,guidance_scale=0.0).images[0]
image
Using these simple lines of code you can have a working text 2 image generation model that can help you in your line of work. You can fine below two sample images generated on my local machine about construction sites & drawings.